Multimodal Large Language Models (MLLMs) have lately become the talk of the AI universe. It is dynamically reshaping how AI systems understand and interact with our complex, multi-sensory world. These multi-sensory inputs that we get can also be coined as our different modalities (images, audio, etc.). From Google’s latest Veo 3, generating state-of-the-art videos to ElevenLabs creating incredibly realistic AI voice overs, these systems are demonstrating capabilities that were once considered to be science fiction.
This comprehensive guide is the first part of a two-part series exploring the intricate world of multimodal LLMs. The second part of this series will explore how these models generate multimodal content and their practical applications across various industries.
Challenges of Multimodality
Multimodality is definitely one of the greatest capabilities and advancements in AI models. However, when we deal with several modalities, there will be certain challenges that need to be curbed. Here are two major challenges we face in this regard:
- How to represent our information?
One of the main challenges of multimodal LLMs is when it comes to representing different types of information. It is how to represent and summarize these multimodal data in a common space which we need to train our multimodal models. - How do we align our different modalities?
We have to ensure we identify direct relations between similar elements from different modalities. This is done in two ways:- Explicit Alignment: Here, we directly find correspondences between elements of different modalities. For this, we have to train our model across various modalities like audio, text, image, etc. This supervised or rule-based alignment is implemented using algorithms like Dynamic Time Warping (DTW), Attention with supervision, or alignment matrices.
- Implicit Alignment: This uses internally latent alignment of modalities to better solve different problems. Allowing the model to figure it out itself. Models use techniques like self-attention, contrastive learning, or co-attention mechanisms to learn which parts of one modality relate to another.

Let’s understand this with a small example:
Since we need to represent the term “cat” whether it’s in the form of text, image, or speech as closely as possible, we should make sure other terms like ”dog” are far from the vicinity of the term “cat”. These embeddings from various modalities need to be correctly aligned across the shared dimensional space.

Representation Learning
The solution to our first problem on “how to represent information” can be solved by representation learning. There are 2 types of representations-based learning through which multimodal information could be understood by these multimodal models. These are: Joint Representation and Coordinated Representation.
Joint Representation
Joint representation could be defined as a single unified representation of different types of information which could be text, image, video, audio, etc. We combine the embeddings of each modality in a single embedding dimension space.

Here, in this approach, we will pass each modality across its respective encoders. Basically, Text will be passed through a Text Encoder (e.g. BERT) and image across an Image Encoder (e.g. VIT) likewise for other modalities.

We get the embeddings for each modality. Later, these embedding representations merge using a concatenation technique. Then, a projection layer or multimodal attention mechanism will assign certain importance to certain features. The resulting joint embedding will contain the complete semantics of all the input modalities.
This entire system is trained. The individual modality encoders, the fusion mechanism, and the final task-specific layers are all optimized together using a single loss function. This unified training setup allows the model to learn cross-modal correlations more effectively, especially when the modalities are strongly interdependent (e.g. image and its caption like in the COCO dataset).
These joint embeddings are particularly useful when the input modalities are closely aligned or when the available training data is limited, as shared representations help in regularizing the learning process and extracting richer, semantically meaningful features from the combined input.
Read more about the Evolution of Embeddings.
Coordinated Representation
Coordinated Representation learning on the other side has a completely different approach. Here, we learn independent representations alone and then coordinate (or align) them together in the fusion stage. In this approach, each modality (text, image, audio, etc.) is handled by its dedicated model, which is trained separately and may also have its loss function and objective.
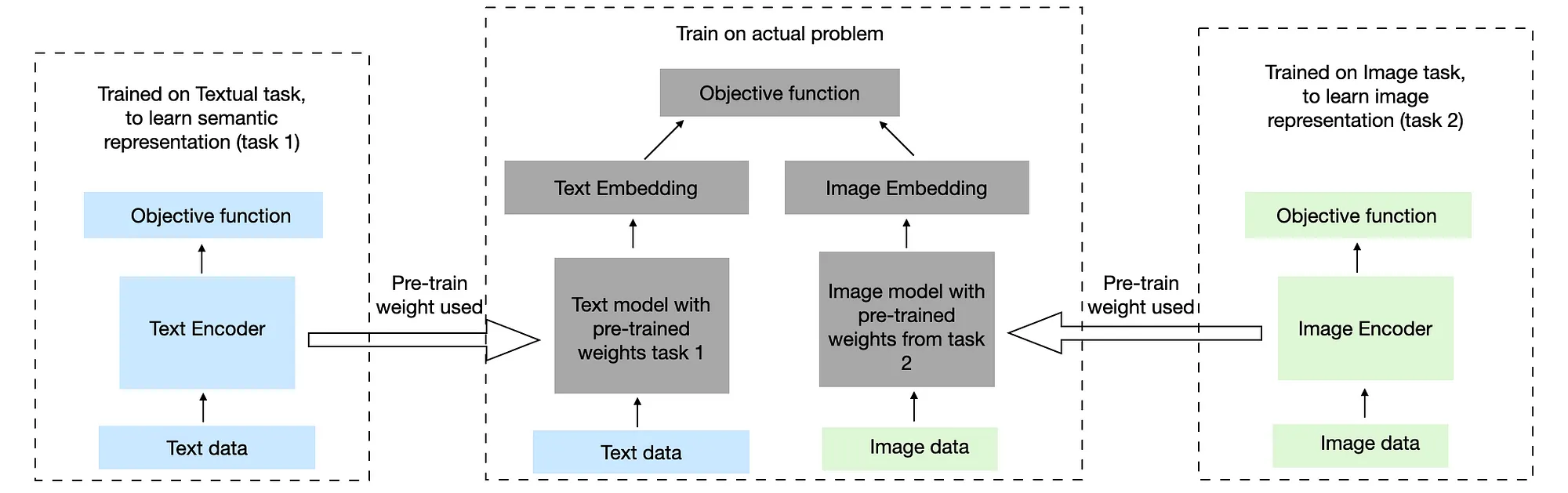
Once these models are trained, their individual output embeddings are combined using a coordinated fusion mechanism like late fusion (simple concatenation), cross-modal attention, or statistical alignment methods such as Canonical Correlation Analysis (CCA). The coordination phase focuses on ensuring that the separate embeddings are semantically aligned with each other so that they can jointly contribute to the final prediction. Unlike joint embeddings, coordinated embeddings allow each modality to preserve its own feature structure without being forced into a shared representation space prematurely.
This method is highly effective when modalities are somewhat independent or loosely coupled, when there is abundant modality-specific data, or when computational resources allow for more extensive pre-training. Coordinated embeddings also offer greater flexibility in model architecture and training pipelines, as each modality can be improved independently before coordination.
Explicit vs Implicit Alignment
Let’s try to tabulate our understanding here:
| Feature | Explicit Alignment | Implicit Alignment |
| Nature | Supervised / Annotated | Unsupervised / Learned during training |
| Need for Labels | Requires aligned or annotated data | Does not require explicit alignments |
| Approach | Manual or rule-based mapping | Learned via attention or contrastive loss |
| Example Tasks | Image captioning with bounding boxes | CLIP, VQA with unsupervised attention |
| Advantages | High precision, interpretable | Scalable, flexible, learn fine-grained links |
| Challenges | Expensive to label, less flexible | Can be less interpretable, data-hungry |
We will now try to understand another important term that we used in the above section named “fusion” next.
If you want to understand how implicit alignment can be done, read this. In this research paper, the model embeds fragments of images (objects in the image) and fragments of sentences (typed dependency tree relations) into a common space.

Let’s dive a little deeper into this.
The Concept of Fusion in Multimodal LLMs
The cornerstone of multimodal learning lies in understanding how different types of data can be combined effectively. In other words, it serves as a way to accurately align our different modalities across a unified dimensional space. Fusion strategies determine when and how information from different modalities is integrated, fundamentally shaping the model’s ability to understand complex multimodal inputs.
Fusion refers to the integration of information from multiple modalities such as text, image, and audio into a unified representation. It plays a critical role in enabling models to leverage complementary information from each modality. The goal is to combine features in such a way that the model can make more informed predictions. It’s pretty similar to the concept of fusion that we use in Deep Learning.
There are two widely used strategies for fusion: Early Fusion and Late Fusion.

There also exists a third category – mid-fusion, about which I will explain in a while.
1. Early Fusion
Early Fusion represents the simplest approach to multimodal integration, here the raw data from different modalities is combined at the input level itself before any processing occurs. In early fusion systems, data from various sources such as pixel values from images and tokenized text are concatenated or combined through simple operations at the very beginning of the processing pipeline. This approach allows for comprehensive interaction between modalities from the earliest stages of computation, enabling the model to capture subtle correlations and dependencies that might be lost in later-stage fusion approaches.
- Process: Raw modalities -> Feature Extraction (low-level features) -> Concatenation/Simple Combination -> Joint Processing by a single model.
- Pros: It allows the model to learn correlations and interactions between modalities from the earliest stages. It can also be conceptually simpler.
- Cons: It can be difficult to implement effectively if modalities have vastly different structures or scales. The combined feature space can become very high-dimensional and unwieldy. It forces a “one-size-fits-all” processing approach early on, which might not be optimal for each modality.
Example: Earlier attempts might involve flattening an image and concatenating it with text embeddings before feeding it into a neural network. This is less common in modern sophisticated multimodal LLMs due to their limitations.
2. Late Fusion
Late Fusion takes the opposite approach, processing each modality independently through specialized networks before combining the results at the decision level. Here separate neural networks process each data type using architectures optimized for that specific modality like convolutional neural networks for images, or transformer architectures for text and VIT for images. The outputs from these specialized processors are then combined using techniques such as weighted averaging, concatenation, or more sophisticated fusion modules.
- Process: Modality A -> Model A -> Output A; Modality B -> Model B -> Output B. Then, Output A and Output B are combined (using averaging, voting, a small neural network, etc.).
- Pros: It allows for optimal, specialized processing of each modality using models best suited for it. It is simpler to implement if you already have strong unimodal models. It’s more robust in missing modalities.
- Cons: It fails to capture low-level features between modalities because they are processed in isolation for too long. Also, the fusion happens too late to influence the feature learning within each modality stream.
Example: An image classifier identifies objects in an image, and a text classifier analyzes a caption. A separate module then combines/fuses these classifications to say if the caption accurately describes the image.
3. Mid Fusion
Mid Fusion or intermediate fusion strikes a balance between early and late approaches by integrating multimodal information at various intermediate layers of the network. This strategy enables the model to capture both low-level cross-modal interactions and high-level semantic relationships. Mid-fusion architectures often employ attention mechanisms or specialized transfer modules that allow information to flow between modality-specific processing streams at multiple points throughout the network. The Multimodal Transfer Module (MMTM) uses this approach by using squeeze and excitation operations to recalculate channel-wise features in each CNN stream based on information from multiple modalities.
- Process: Modality A -> Partial Processing A -> Features A; Modality B -> Partial Processing B -> Features B. Then, Features A and Features B are combined and fed into a joint multimodal processing network.
- Pros: It allows specialized initial processing while still enabling the model to learn rich cross-modal relationships at a deeper feature level. It also offers more flexibility.
- Cons: It can be more complex to design and train. Finding the optimal point and method of fusion can be challenging in this case.
Example: Most modern vision-language models (like LLaVA) use this. An image encoder processes the image into a set of feature vectors, and a text encoder processes the text into token embeddings. These are then projected and combined in a way that allows a central LLM to attend to both.
Core Encoder Architectures
Let’s now try to get an over-the-top understanding of some widely used encoders that are utilized in the VLMS.
If you would like to learn more about various Large Vision Language model architectures click here.
CLIP: Contrastive Language-Image Pre-training
CLIP represents a foundational breakthrough in multimodal learning, introducing a simple yet powerful approach to learning joint representations of images and text through contrastive pre-training. The architecture consists of two separate encoders: a vision encoder that processes images and a text encoder that processes natural language descriptions. These encoders are trained jointly using a contrastive objective that encourages the model to associate images with their corresponding textual descriptions while distinguishing them from unrelated text-image pairs.

The training process for CLIP involves presenting the model with batches (for the sake of understanding the above image let’s say n=5) of n image-caption pairs, where each image is paired with its correct textual description. The model computes embeddings for all images and texts in the batch, creating two sets of n-dimensional vectors.
The contrastive loss function encourages high similarity between correct image-text pairs while penalizing high similarity between incorrect pairs. As we can visualize in the above image the diagonal weights will be maximized and the rest will be penalized. Mathematically, this is expressed as a symmetric cross-entropy loss over similarity scores, where the temperature parameter controls the sharpness of the distribution.
CLIP’s effectiveness came from its ability to learn from naturally occurring image-text pairs found on the internet (400 million scrapped information from the web), eliminating the need for manually annotated datasets. This approach enables the model to learn rich semantic relationships that generalize well to downstream tasks. The learned representations demonstrate remarkable zero-shot capabilities, allowing the model to perform image classification and retrieval tasks on categories it has never seen during training. The success of CLIP has inspired numerous follow-up works and established contrastive pre-training as a dominant methodology in multimodal learning.
Also, do consider reading about ViT here.
SigLIP: Sigmoid Loss for Improved Efficiency
SigLIP represents an evolution of the CLIP architecture that addresses some of the computational limitations of the original contrastive approach. While CLIP requires computing similarities between all pairs of images and texts in a batch, SigLIP employs a pairwise sigmoid loss that operates on individual image-text pairs independently. This modification eliminates the need for a global view of all pairwise similarities within a batch, enabling more efficient scaling to larger batch sizes while maintaining or improving performance.
The sigmoid loss function used in SigLIP offers several advantages over the traditional contrastive loss. It provides a more stable training mechanism and better performance with smaller batch sizes, making the approach more accessible with limited computational resources. The pairwise nature of the loss enables more flexible training configurations and better handling of datasets with varying numbers of positive examples per sample.
SigLIP’s architecture maintains the dual-encoder structure of CLIP but incorporates architectural improvements and training optimizations that enhance both efficiency and effectiveness. The model uses separate image and text encoders to generate representations for both modalities, with the sigmoid loss encouraging similarity between matched pairs and dissimilarity between unmatched pairs. This approach has demonstrated superior performance across various image-text tasks while offering improved computational efficiency compared to traditional contrastive methods.

RoPE: Rotary Position Embedding
Although RoPE can’t be considered as an encoder model, it definitely is an embedding strategy widely used in large language models.
Rotary Position Embedding (RoPE) represents a sophisticated approach to encoding positional information in transformer-based architectures. RoPE encodes the absolute positional information using rotation matrices while naturally including the explicit relative position dependencies in self-attention formulations. This approach provides valuable properties including flexibility to expand to any sequence length, decaying inter-token dependency with increasing relative distances, and the capability to equip linear self-attention with relative position encoding.
The mathematical foundation of RoPE involves applying rotation matrices to embedding vectors based on their positions in the sequence. This rotation-based approach ensures that the dot product between embeddings captures both content similarity and relative positional relationships. The decay property of RoPE means that tokens that are farther apart in the sequence have naturally reduced attention weights, which aligns well with many natural language and multimodal tasks where local context is typically more important than distant context.

In multimodal applications, RoPE enables models to handle variable-length sequences more effectively, which is crucial when processing multimodal data where different modalities may have different temporal or spatial characteristics. The ability to extrapolate to longer sequences than those seen during training makes RoPE particularly valuable for multimodal models that need to handle diverse input formats and lengths.
Case Studies in Vision-Language Models
Now, let’s see how these concepts and components come together in some open-sourced influential multimodal LLMs, particularly focusing on how they “see.”
1. LLaVA (Large Language and Vision Assistant)
LLaVA’s core idea is to demonstrate that a remarkably simple architecture can achieve impressive visual reasoning capabilities by efficiently connecting a pre-trained vision encoder (from CLIP) to a pre-trained Large Language Model (Vicuna) using a single, trainable linear projection layer. It leverages the strong existing capabilities of these unimodal models for multimodal understanding.

Training Process
LLaVA utilizes pre-trained Vicuna LLM and CLIP vision encoder components. The training is a 2-stage instruction-tuning procedure:
Stage 1: Visual Feature Alignment (Pre-training)
- Goal: Teach the projection layer to map visual features into the LLM’s word embedding space.
- Data: A subset of Conceptual Captions (CC3M), containing image-caption pairs.
- Method: The image is fed through the (frozen) CLIP-ViT. The output visual features are passed through the (trainable) linear projection layer. These projected visual tokens are prepended to the tokenized caption. The Vicuna LLM (frozen) is then tasked with autoregressively predicting the caption. Only the linear projection layer’s weights are updated.
Stage 2: Instruction Fine-tuning (End-to-End)
- Goal: Improve the model’s ability to follow instructions and engage in complex visual dialogue.
- Data: A small, high-quality synthetically generated dataset (LLaVA-Instruct-158K) using GPT-4 to create varied questions about images, detailed descriptions, and complex reasoning tasks. This dataset includes – Multimodal conversations (58k), Detailed Text Descriptions of images (23k), and Complex reasoning/complex visual QA (77k).
- Method: Both the projection layer and the LLM weights are fine-tuned on this instruction dataset. The input to the LLM is a combination of projected image features and a textual instruction/question.
Working
The LLaVA model processes inputs which can be text, an image, or a combination. Here’s how it works:
- Text Input: Vicuna’s native tokenizer and embedding system prepares the provided text (e.g. a question) for the LLM by tokenizing and embedding it.
- Image Input: The CLIP vision encoder (specifically, its Vision Transformer, ViT) extracts rich visual features from the image. These features, typically representing image patches, are a sequence of vectors.
- Projection: These visual feature vectors then pass through the MLP Projection Layer. This layer performs a linear transformation, projecting the visual features into the same dimensionality as Vicuna’s word embeddings. This makes the visual information “look like” word tokens to the LLM.
- Combined Input to LLM: The model then combines the projected visual tokens with the text token embeddings (e.g., by prepending the visual tokens to the text tokens).
- LLM Processing (Fusion & Reasoning): This combined sequence is fed into the Vicuna LLM. The LLM’s attention mechanisms process both types of tokens simultaneously. This is where “Fusion” happens, allowing the model to correlate parts of the text with relevant visual tokens. The goal is to achieve Joint embedding (a shared representation space) and Implicit Alignment (connecting visual concepts to textual ones).
- Output Generation: Based on the processed combined input, the LLM autoregressively generates a textual response to the query or instruction.

Simplified Version
LLaVA looks at an image and creates captions for the images using CLIP (vision encoder). A special translator (projection layer) changes these captions into a language the Vicuna LLM understands. The Vicuna brain then reads both the translated captions and any actual text words (like your question). Finally, the Vicuna brain uses all this information to give you an answer in the text.
Encoder-Decoder Architecture
While not a traditional encoder-decoder in the sequence-to-sequence translation sense, LLaVA uses components that serve these roles:
- Vision Encoder: A pre-trained CLIP ViT-L/14. This model takes an image and outputs visual embeddings (features).
- Language Model (acts as Decoder): Vicuna (an instruction-tuned Llama variant). It takes the visual embeddings (after projection) and text embeddings as input, and autoregressive generates the text output.
- Connector/Projector (The “Bridge”): A single linear MLP layer. This is the key new component that translates visual features from the vision encoder’s space to the LLM’s input embedding space.
Strengths
- Simplicity & Efficiency: Remarkable performance for its relatively simple architecture and efficient training (especially Stage 1).
- Leverages Pre-trained Models: Effectively utilizes the power of strong, readily available pre-trained vision (CLIP) and language (Vicuna) models.
- Cost-Effective Fine-tuning: The initial feature alignment stage only trains a small projection layer, making it computationally cheaper.
- Instruction Following: The LLaVA-Instruct-158K dataset was crucial for enabling strong conversational and instruction-following abilities.
- Open Source: Contributed significantly to open research in vision-language models.
Limitations
- Granularity (Early Versions): Original LLaVA often relied on a single global feature vector or a small sequence from the image (e.g., [CLS] token features), which could limit the understanding of very fine-grained details or complex spatial relationships. (Later versions like LLaVA-1.5 improved this by using more patch features and an MLP projector).
- Hallucination: Can sometimes “hallucinate” objects or details not present in the image, a common issue with LLMs.
- Reasoning Depth: While good, reasoning on very complex scenes or abstract visual concepts might be limited compared to larger, more extensively trained models.
- Dataset Dependency: Performance is heavily influenced by the quality and nature of the instruction-tuning dataset.
2. Llama 3 Vision (Llama 3.1 Vision 8B / 70B)
Llama 3 Vision aims to build state-of-the-art open-source multimodal models by integrating a powerful vision encoder with the strong base of Llama 3 LLMs. The core idea is to leverage Meta’s advancements in LLMs, vision models, and large-scale training methodologies to create models that can perform complex visual reasoning, understand nuanced visual details, and follow intricate instructions involving images and text.
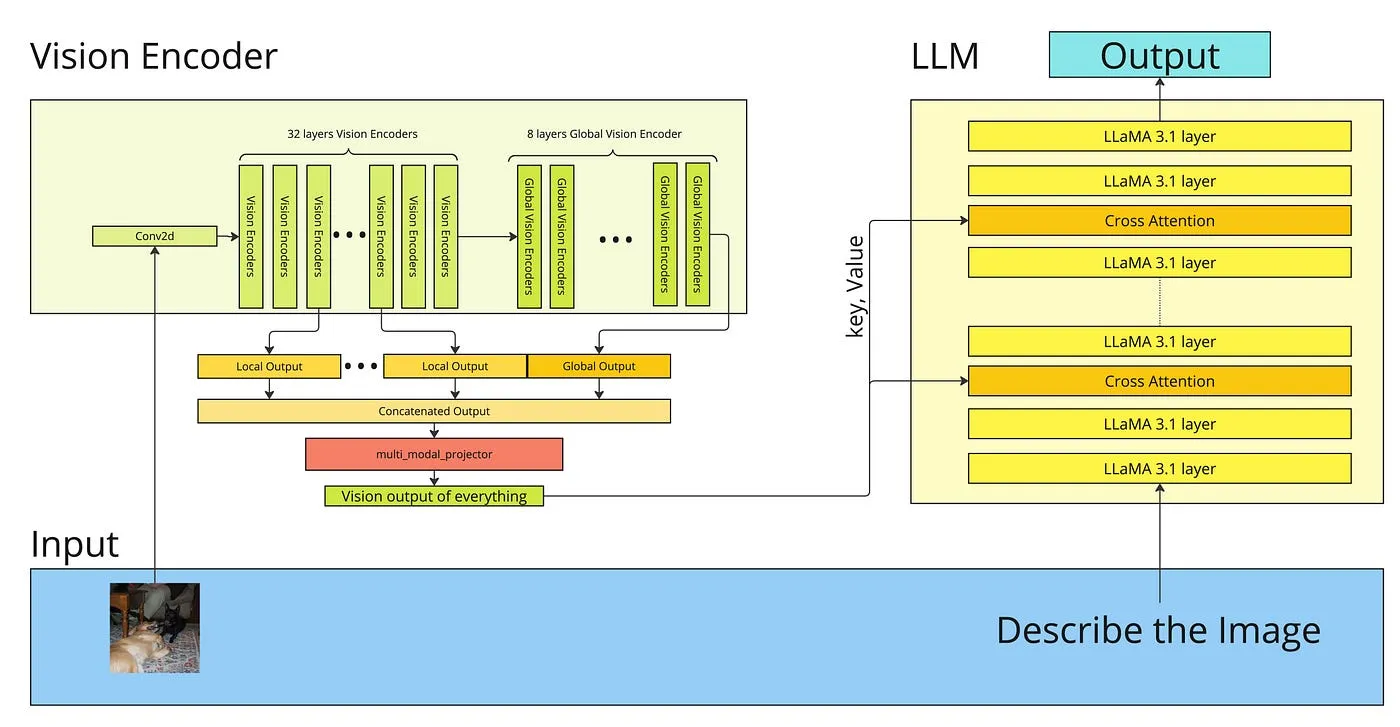
Training Process
Llama 3 Vision models leverage pre-trained Llama 3 LLMs and powerful pre-trained vision encoders (e.g., CLIP ViT). The training strategy typically involves:
Stage 1: Large-Scale Multimodal Pre-training
- Goal: Teach the model fundamental visual concepts and their deep alignment with language at a massive scale.
- Data: Billions of image-text pairs from diverse sources (e.g., publicly available web data, licensed datasets). Meta has access to vast (anonymized and privacy-preserving) image-text data.
- Method: The vision encoder, a projector module (e.g., a two-layer MLP), and the Llama 3 LLM are trained jointly. The model learns to predict text associated with images or masked portions of text/images. This stage trains the projector and fine-tunes both the vision encoder and the LLM for multimodal understanding.
Stage 2: Instruction Fine-tuning (End-to-End)
- Goal: Enhance the model’s ability to follow diverse instructions, engage in dialogue, and perform specific multimodal tasks.
- Data: A curated mix of high-quality multimodal instruction-following datasets. This includes Visual Question Answering (VQA), image captioning, visual reasoning, object grounding, Optical Character Recognition (OCR) in images, chart/diagram understanding, etc.
- Method: The entire model (or significant parts of it) is fine-tuned on these instruction datasets to improve its helpfulness, safety, and task-specific performance.
- Scaling: Meta emphasizes scaling laws, meaning Llama 3 Vision benefits from scaling up the LLM size (e.g., 8B to 70B), the vision encoder size, and the training data volume and quality.

Working
Llama 3 Vision processes image and text inputs to generate textual outputs.
- Text Input: Text (e.g., questions, instructions) is tokenized using Llama 3’s advanced tokenizer (e.g., 128k vocabulary) and converted into token embeddings.
- Image Input: The input image is preprocessed (e.g., scaled to a resolution like 448×448 for Llama 3.1 Vision). It’s then fed into a powerful vision encoder (e.g., a CLIP ViT model). The vision encoder processes the image and outputs a sequence of visual embeddings, representing numerous image patches (e.g., Llama 3.1 Vision produces 144 visual tokens from a CLIP ViT-L/14).
- Projection: These visual embeddings are passed through a projector module, typically a multi-layer perceptron (e.g., a two-layer MLP in Llama 3.1 Vision). The projector transforms these visual features into embeddings that are compatible with the Llama 3 LLM’s input space.
- Combined Input to LLM: The projected visual tokens are combined with the text token embeddings. Special image tokens might be used to demarcate visual information within the sequence.
- LLM Processing (Fusion & Reasoning): The Llama 3 LLM processes this interleaved sequence of visual and textual tokens. Its sophisticated attention mechanisms (Grouped Query Attention for efficiency with long sequences) allow it to deeply integrate and correlate information from both modalities. This enables Joint embedding and Implicit Alignment at a very fine-grained level.
- Output Generation: The LLM leverages its vast pre-trained knowledge, detailed visual information, and the textual context to perform reasoning and generate a coherent and relevant textual response.
Simplified Version
Llama 3 Vision uses a very sharp ViT variant model to look at an image, breaking it down into many detailed picture words(patch info). A projector makes these detailed image captions ready for the super-smart Llama 3 LLM. The Llama 3 brain reads these captions along with any text questions you ask it. Because the Llama 3 brain is so big and well-trained, it can understand complex things in the picture and give you very detailed and intelligent answers in the text.
Encoder-Decoder Architecture
Similar to LLaVA, it’s a vision encoder + projector + LLM architecture:
- Vision Encoder: A powerful, pre-trained Vision Transformer. For Llama 3.1 Vision, this is a CLIP ViT model, potentially a large variant.
- Language Model (acts as a Decoder): The Llama 3 model (e.g., Llama 3 8B or Llama 3 70B), which is an autoregressive decoder.
- Connector/Projector: A learnable module, typically an MLP (e.g., a two-layer MLP for Llama 3.1 Vision) to map the sequences of visual features from the ViT output into the LLM’s input embedding space.

Strengths
- State-of-the-Art Performance: Aims for top-tier performance on a wide range of vision-language benchmarks due to scale and advanced training.
- Scale: Benefits from large base LLMs (Llama 3 8B, 70B), powerful vision encoders, and massive training datasets.
- Strong Base LLM: Built upon the highly capable Llama 3 models known for excellent text generation and reasoning.
- Improved Reasoning & Reduced Hallucination: Extensive pre-training and fine-tuning on high-quality, diverse data help improve reasoning and reduce the tendency to hallucinate.
- Advanced Capabilities: Shows strong performance in areas like OCR, understanding charts/graphs, and fine-grained visual detail recognition.
- Architectural Refinements: Leverages LLM advancements like Grouped Query Attention (GQA) for efficient handling of long sequences (including visual tokens).
Limitations
- Computational Cost: Larger models (like 70B) require significant computational resources for training and inference.
- Data Dependency & Bias: Performance and potential biases are still dependent on the vast datasets used for training. Ensuring fairness and mitigating harmful biases is an ongoing challenge.
- Hallucination: While reduced, the risk of generating plausible but incorrect information (hallucination) persists, especially for out-of-distribution or highly ambiguous inputs.
- Complexity: The increased scale and complexity can make debugging, interpretation, and fine-tuning more challenging for end-users compared to simpler models.
Advancements in Llama 4
While specific, verified details for Llama 4 are still emerging, discussions around its advancements often center on tackling the inherent challenges of large-scale multimodal learning, particularly through architectural innovations like Mixture-of-Experts (MoE).

1. Addressing Computational Complexity and Scalability with MoE
A key conceptual advancement for Llama 4 is the effective implementation of MoE. This architecture significantly mitigates computational costs by activating only a relevant expert. This allows for enhancing model capacity while keeping the computational load for training and inference manageable.
Such efficiency is crucial for handling increasingly large, high-resolution multimodal datasets and long sequence lengths, which would otherwise be bottlenecked by the quadratic scaling of traditional attention mechanisms. This also enables broader scalability solutions, allowing the model to learn from more extensive and diverse data.
2. Improved Alignment of Heterogeneous Data
With the capacity afforded by MoE and advancements in training strategies, Llama 4 would aim for a more sophisticated alignment of diverse modalities like images and text. This involves developing more robust representations that can capture modality-specific characteristics (e.g., spatial correlations in vision, semantic rules in text) while enabling deeper cross-modal understanding and interaction.
Llama4 architecture also mentions the use of the Early Fusion mechanism to align the embeddings into a unified representation space. While not its primary purpose, the increased capacity and specialization within an MoE framework could indirectly aid in better handling statistical and even temporal discrepancies between modalities if trained on appropriate data.
3. Enhanced Robustness and Bias Mitigation
Models like Llama 4 are expected to incorporate more advanced strategies to address inherited biases and improve overall robustness. Llama 4 would aim to:
- Implement more comprehensive bias mitigation techniques during pre-training and fine-tuning to reduce the amplification of biases through cross-modal interactions.
- Build greater resilience to input quality variations, out-of-distribution data, and adversarial attacks that might exploit cross-modal vulnerabilities. The goal is to achieve more reliable and secure performance across a wider range of real-world scenarios.
Conclusion
The evolution of multimodal LLMs represents one of the most significant advances in artificial intelligence, fundamentally changing how machines perceive and interact with the world around us. From the foundational concepts of early and late fusion to the sophisticated architectures of modern systems like Llama 4, we have traced the technical journey that has enabled AI systems to understand and process multiple modalities with human-like sophistication. The technical foundations we explored including contrastive learning principles, joint embedding spaces, and alignment mechanisms provide the theoretical framework that makes multimodal understanding possible.
Our case studies of LLaVA, Llama 3.2 Vision, and Llama 4 illustrate the rapid progression of multimodal capabilities. LLaVA demonstrated that elegant simplicity could achieve remarkable results through visual instruction tuning. Llama 3.2 Vision showed how sophisticated cross-attention mechanisms could enable robust multimodal reasoning. Llama 4 represents the current state-of-the-art, introducing mixture-of-experts architectures and unprecedented context lengths that open entirely new categories of applications. In the second part of this series, we will explore how these Multimodal LLMs are able to understand audio.
GenAI Intern @ Analytics Vidhya | Final Year @ VIT Chennai
Passionate about AI and machine learning, I’m eager to dive into roles as an AI/ML Engineer or Data Scientist where I can make a real impact. With a knack for quick learning and a love for teamwork, I’m excited to bring innovative solutions and cutting-edge advancements to the table. My curiosity drives me to explore AI across various fields and take the initiative to delve into data engineering, ensuring I stay ahead and deliver impactful projects.
Login to continue reading and enjoy expert-curated content.